Technical SEO is the part of search optimization that makes a website discoverable, understandable and dependable. It is not a magic layer that ranks weak content by itself, and it is not a collection of intimidating settings only developers can touch. At its best, technical SEO removes friction: search engines can crawl important pages, index the right versions, follow useful internal links and interpret the structure of the site with fewer mixed signals.
This guide is written for webmasters who manage real websites, not theoretical diagrams. It explains crawlability, indexing, canonicalization, redirects, internal linking, structured data, JavaScript rendering, sitemaps, pagination and audit routines in practical language. The goal is to help you know what to check, why it matters and how to avoid common mistakes that can quietly limit organic traffic.
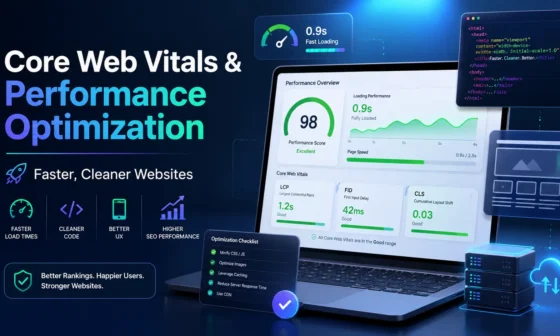
Technical SEO works best when it is part of a broader operating system. If your site is unstable, outdated or full of broken forms, start with the website maintenance checklist for webmasters. If your pages are crawlable but slow or unstable for users, pair this article with the Core Web Vitals performance guide. Search visibility improves when the platform, content and user experience support each other.
For an evergreen site, the aim is not to chase every rumor about algorithms. It is to build a clean technical foundation that stays sensible through updates: clear URLs, useful content, fast templates, accurate metadata, logical links, controlled duplication and pages that return the status codes they should return. Those basics never stop mattering.
| Technical SEO layer | Question it answers | Common failure |
|---|---|---|
| Crawlability | Can search engines reach the page? | Blocked URLs, broken internal links, accidental robots rules |
| Indexing | Should this page appear in search results? | Noindex mistakes, duplicate low-value pages, thin archives |
| Canonicalization | Which version is the preferred version? | Competing URLs, parameter duplicates, inconsistent canonicals |
| Internal links | How does authority and context move through the site? | Orphan pages, weak anchor text, unbalanced navigation |
| Structured data | Can machines understand page entities and purpose? | Invalid schema, unsupported markup, mismatched content |
| Performance | Can users load and interact with the page comfortably? | Heavy templates, poor caching, intrusive third-party scripts |
Technical SEO Starts With Search Engine Access
The first question is simple: can search engines reach the pages that matter? Before worrying about advanced schema or tiny title changes, confirm that important URLs are not blocked by robots.txt, hidden behind login walls, buried without internal links, returning server errors or accidentally marked noindex. If access is broken, every later optimization becomes less effective.
Crawlability is not the same as indexing. A search engine may crawl a page and still decide not to index it. It may also discover a URL but avoid crawling it often because the site sends weak signals. Technical SEO begins by separating these stages. Discovery, crawling, rendering, indexing and ranking are related, but each can fail for different reasons.
For webmasters, the practical job is to reduce confusion. Search engines should see a coherent site where important pages are easy to find, duplicate versions are controlled, navigation is logical and server responses are reliable. The more contradictions you create, the more crawling and indexing become unpredictable.
Access checks should happen after launches, migrations, theme changes, plugin changes and server changes. Many serious technical SEO problems are accidental. A staging noindex rule moves to production. A robots.txt file blocks a new directory. A redirect sends users to the right place but gives crawlers a chain of unnecessary hops. Routine checks catch these issues early.
Robots.txt: Use It for Crawl Guidance, Not Index Control
Robots.txt tells compliant crawlers which areas they should not crawl. It is useful for reducing crawl waste on areas like internal search results, certain parameter combinations or private utility paths. However, robots.txt is not the right tool for removing a page from search results. A blocked URL can still appear if other pages link to it, and crawlers may not see the noindex directive if they are blocked from crawling the page.
Use robots.txt carefully. Blocking CSS or JavaScript can prevent search engines from rendering pages properly. Blocking whole folders because they look technical can hide resources needed for layout, navigation or content. A rule that seems harmless in one CMS can be harmful after a theme or plugin change. Always test important templates after robots changes.
Keep the file readable. A small robots.txt file with clear intent is safer than a long file full of legacy rules no one understands. Add comments for unusual decisions. If a rule exists only because of an old campaign or outdated plugin, remove it after confirming it is no longer needed. Technical debt in robots.txt can last for years.
When you truly do not want a page indexed, use an appropriate noindex directive on a crawlable page, password protection for private content, or removal tools for urgent cases. Robots.txt can help manage crawling, but it should not be treated as a privacy or deindexing system.
XML Sitemaps: Submit a Clean Map, Not Every URL You Can Find
An XML sitemap should help search engines discover canonical, indexable, valuable URLs. It is not a dumping ground for every page a CMS can generate. Including redirects, noindex pages, parameter duplicates, thin archives or broken URLs sends mixed signals. A clean sitemap says, “These are the pages we believe matter.”
Large sites should split sitemaps logically: posts, pages, products, categories, videos or news if relevant. Splitting does not guarantee better rankings, but it makes diagnostics easier. If one section has errors, you can identify the affected content type quickly. For webmasters managing many templates, that clarity saves time.
Update frequency and lastmod values should be honest. If every URL claims to change daily when it does not, the signal becomes less useful. If lastmod updates only because a plugin regenerated the sitemap, it may not reflect meaningful content changes. Search engines are good at judging patterns, so use metadata to clarify rather than exaggerate.
After submitting a sitemap, monitor whether submitted URLs are indexed and whether excluded URLs reveal a pattern. Exclusion is not always a problem. A thank-you page or duplicate archive may not need indexing. The useful question is whether important pages are missing and whether unimportant pages are consuming attention.
Status Codes and Redirects: Make Every Response Tell the Truth
Status codes are technical signals with practical consequences. A 200 response says the page exists. A 301 says it moved permanently. A 302 says the move is temporary. A 404 says the page is not found. A 410 says it is gone. A 5xx error says the server failed. Search engines and browsers use these signals to decide what to do next.
Redirects should be direct and purposeful. A deleted article with a close replacement can redirect to that replacement. An old product category can redirect to the current category. But redirecting every removed page to the homepage is usually poor experience. It confuses users and weakens topical relevance. If no useful replacement exists, a helpful 404 or 410 may be more honest.
Redirect chains waste time and create fragility. URL A should not redirect to B, then C, then D. Clean chains during migrations, HTTPS moves, domain changes and permalink updates. One hop is better than several. Also avoid redirect loops, which can make a page inaccessible entirely.
Server errors deserve immediate attention when they affect important pages. A temporary 500 on an obscure URL may not matter much, but repeated errors on key templates can reduce trust and crawl efficiency. Monitor logs, Search Console reports and uptime tools to identify whether errors are isolated or systemic.
Indexing Decisions: Choose What Deserves Search Visibility
Not every page should be indexed. Search results should include pages that satisfy search intent, offer unique value and represent the site well. Thin tag archives, duplicate filter pages, internal search results, login pages, cart pages, staging pages and low-value utility URLs usually do not belong in search. Technical SEO includes saying no.
The noindex directive is a precise tool when used correctly. It is useful for pages that users may access but search engines should not show. However, noindex should not be added casually. If you noindex a category, author archive or pagination path without understanding its role, you may weaken discovery for deeper content.
Indexing problems often appear after CMS changes. A plugin may add indexable archives. A theme may create author pages. A faceted navigation system may generate thousands of URL combinations. A search page may become crawlable. Each feature may be useful for users, but not every generated URL should become a search landing page.
Make index decisions based on value and uniqueness. If a page has a distinct audience, useful content and a role in the site structure, it may deserve indexing. If it is merely a rearrangement of other content without added value, control it with noindex, canonical tags, parameter handling, internal linking choices or template changes.
Canonical Tags: Reduce Duplicate Signals Without Hiding Problems
Canonical tags tell search engines which version of similar or duplicate content you prefer. They are useful for HTTP versus HTTPS, trailing slash variations, tracking parameters, printer-friendly versions, syndicated content, product variants and repeated listing pages. A canonical tag is a hint, not a force field. Search engines can ignore it when other signals disagree.
Canonical tags should be self-consistent. A page that returns 200, appears in the sitemap, receives internal links and has a canonical pointing elsewhere sends mixed messages. Sometimes that is intentional, but often it is accidental. If a page is not meant to be indexed, ask whether canonical, noindex, redirect or content consolidation is the right solution.
Avoid canonical chains. If page A canonicals to B and B canonicals to C, you have created unnecessary ambiguity. Canonical targets should usually be indexable, crawlable, return 200 and represent the version you genuinely want users to find. Broken canonical targets are a common technical SEO mistake on older sites.
For WordPress and other CMS platforms, plugins often generate canonicals automatically. Automation is helpful, but review important templates manually. Check posts, pages, categories, paginated archives, product variants and filtered URLs. One wrong setting can repeat across thousands of pages.
URL Structure: Make Addresses Durable and Understandable
Good URLs are readable, stable and aligned with the page’s role. They do not need to include every keyword. They should help users and site managers understand where they are. A durable URL avoids unnecessary dates, random IDs, changing campaign words and fragile category paths unless those elements serve a real purpose.
Changing URLs is expensive because it requires redirects, internal link updates, sitemap updates and possible temporary ranking volatility. Do not change established URLs for minor wording preferences. If a URL is clear enough and already performs, leave it alone. URL redesigns should solve real structural problems, not cosmetic discomfort.
Consistency matters. Choose lowercase, hyphen-separated slugs, a clear trailing slash policy and one preferred protocol and host. Avoid multiple accessible versions of the same page. Technical SEO often improves when the site stops creating alternate addresses for identical content.
For content sites, simple slugs often work well. For ecommerce and large catalogs, categories can help users, but deep paths can become difficult when products move. Choose a structure you can maintain for years. The best URL system is not only SEO-friendly; it is operationally realistic.
Internal Linking: Build Pathways for Users and Crawlers
Internal links are the site’s nervous system. They help readers move to related information and help search engines understand hierarchy, importance and topical relationships. A strong internal linking strategy does not mean adding random links to every paragraph. It means connecting pages where the next click genuinely helps the reader.
Orphan pages are a common problem. A page may exist in the CMS and even appear in the sitemap, but if no meaningful page links to it, users and crawlers receive weak signals. Important content should be linked from navigation, category hubs, related guides, contextual article links or resource pages. Discovery should not depend entirely on the sitemap.
Anchor text should be descriptive without sounding mechanical. “Read our technical SEO checklist” is more helpful than “click here.” Exact-match anchors repeated unnaturally across a site can look forced. Natural variation is better: describe the destination in language that fits the sentence.
As the content library grows, internal links need maintenance. Older articles may not point to newer cornerstone resources. New guides may lack links from established pages. A quarterly internal link review can lift important evergreen content without publishing anything new.
Information Architecture: Organize the Site Around Real Topics
Information architecture is the planning layer behind navigation, categories, hubs and templates. It decides how content is grouped and how users move from broad questions to specific answers. Search engines can infer structure from links and URLs, but webmasters should make the structure obvious rather than accidental.
A category should represent a meaningful topic, not a dumping bucket. Too many categories create thin archives and editorial confusion. Too few categories make browsing difficult. For a webmaster category, subtopics might include security, performance, technical SEO, analytics, accessibility and WordPress operations. The structure should match what readers actually look for.
Hub pages can strengthen evergreen content. A hub introduces a topic, links to detailed guides and gives readers a path based on their needs. It can also help distribute internal authority to deeper articles. A good hub is curated, not auto-generated. It should explain why each linked resource matters.
Navigation should prioritize usefulness over completeness. Every page cannot be in the main menu. Use menus for key areas, breadcrumbs for hierarchy, related links for context and search for discovery. A balanced architecture helps both new visitors and returning users find the right depth quickly.
Structured Data: Help Machines Understand What Users Can See
Structured data adds machine-readable context to visible content. It can identify articles, products, FAQs, breadcrumbs, organizations, authors, reviews, videos, events and more. The key rule is alignment: markup should describe content that actually appears on the page. Adding schema for information users cannot see is risky and unhelpful.
For many webmaster sites, the most useful structured data types are Article, BreadcrumbList, Organization, WebSite, FAQPage when appropriate and sometimes HowTo for process-based pages. Ecommerce sites may use Product markup, but it must match real product details. Local businesses may use LocalBusiness markup with accurate contact and location data.
Validation is necessary but not sufficient. A page can pass a schema test and still have poor implementation if the markup is irrelevant or misleading. Review structured data from the reader’s perspective. Does it describe the page honestly? Does it reflect the main content? Is it duplicated across templates in ways that create confusion?
Structured data should be maintained after template changes. A redesign can remove visible FAQ sections while the old FAQ schema remains. A plugin update can alter author data. A product field can become empty. Include schema checks in technical audits so rich data stays accurate.
JavaScript SEO: Make Important Content Render Reliably
Modern websites often rely on JavaScript for menus, filters, comments, personalization, product options and entire front-end frameworks. Search engines can render JavaScript, but rendering adds complexity. If important content, links or metadata appear only after scripts run, webmasters should verify that crawlers can see them reliably.
The safest approach is to serve essential content and links in the initial HTML when possible. JavaScript can enhance the experience, but the page should not become empty or unusable when scripts fail. This principle helps search engines, accessibility tools, slower devices and users with blocked scripts.
Check rendered HTML, not only the browser view. Browser tools, URL inspection and crawling software can show whether links and content appear after rendering. Pay attention to client-side routes, infinite scroll, tabbed content, filters and pagination. If a crawler cannot reach deeper items through normal links, valuable pages may be under-discovered.
JavaScript SEO is not a reason to avoid modern frameworks. It is a reason to choose rendering strategies carefully: server-side rendering, static generation, hydration, progressive enhancement and clean links can all help. The right approach depends on the site, but the principle remains the same: important content should not depend on fragile execution.
Pagination, Facets and Filters: Control Large Sets of Pages
Large sites often generate many list pages: categories, tags, archives, filters, search results and pagination. These pages can help users browse, but they can also create crawl bloat and duplication. Technical SEO for large sets is about deciding which combinations deserve discovery and which should stay out of the index.
Pagination should provide crawlable paths to deeper content. If page two, three and beyond are hidden behind scripts or blocked incorrectly, older articles or products can become hard to discover. At the same time, paginated pages may not all need to rank independently. The structure should support discovery without flooding search results with weak pages.
Faceted navigation is powerful and dangerous. Filters by color, size, price, brand, rating and availability can generate thousands of combinations. Some combinations may match search demand, while many are near duplicates. Webmasters should define indexable filter rules deliberately instead of letting every parameter become crawlable and indexable.
Internal search result pages usually should not be indexed because they can create thin, low-quality search landing pages. If your internal search creates public URLs, decide how crawlers should treat them. A small rule here can prevent a large index quality problem later.
Mobile Technical SEO: Design for the Primary Experience
Mobile is not a secondary version of the web for many sites; it is the main experience. Technical SEO must reflect that reality. Navigation, content, structured data, internal links, images, forms and performance should work on mobile without hidden compromises. A desktop-perfect page that becomes frustrating on a phone is not truly optimized.
Check whether mobile pages contain the same essential content as desktop pages. Some responsive designs hide sections for layout reasons. Hiding decorative elements is fine; hiding important text, links, FAQs or product information can create problems. The mobile page should answer the same intent as the desktop page.
Tap targets, sticky elements, cookie notices and ad placements affect usability. A page can be crawlable yet unpleasant if overlays block content or buttons are too close together. Technical SEO and user experience overlap here. Search visibility benefits when users can actually read and interact with the page.
Test mobile templates on real devices when possible. Emulators help, but real phones reveal awkward spacing, slow interactions, keyboard behavior and network conditions. Webmasters responsible for traffic should experience the site the way visitors do, not only through desktop dashboards.
WordPress Technical SEO: Useful Defaults Still Need Review
WordPress can be technically strong when configured carefully, but it can also generate clutter. Tags, author archives, date archives, attachment pages, search pages, pagination, plugin assets and duplicate paths may appear without much thought. A webmaster should decide which WordPress-generated pages support the site and which should be controlled.
SEO plugins are helpful for titles, descriptions, sitemaps, canonicals and schema, but they cannot understand strategy by themselves. They may offer settings for noindexing archives, managing breadcrumbs or editing social previews. Use these tools deliberately. A checkbox can affect hundreds or thousands of URLs.
Permalink settings should be chosen early and changed rarely. If you inherit a site with poor permalinks, evaluate whether a change is worth the redirect work. For established content, stable URLs often matter more than ideal-looking URLs. If a migration is necessary, map old to new carefully and test redirects before launch.
WordPress themes and builders can affect technical SEO through heading structure, schema duplication, script load, image handling and mobile layout. Do not judge a theme only by its visual design. Inspect the HTML, speed, accessibility and template consistency. The prettiest theme can still create avoidable technical problems.
Audit Workflow: Diagnose Before You Fix
A technical SEO audit should move from broad signals to specific causes. Start with crawl data, Search Console reports, analytics trends, sitemaps, robots.txt, status codes, index coverage, page templates and internal links. Then investigate patterns. Are problems concentrated in one template? One content type? One date range? One plugin?
Avoid treating every audit warning as equally important. Crawling tools are useful, but they often produce long lists that mix serious issues with minor preferences. Prioritize by impact: important pages, revenue paths, indexable content, crawl blockers, server errors, broken internal links and large-scale duplication should come before cosmetic warnings.
Document fixes with evidence. For each issue, note the affected URLs, why it matters, the recommended action, the owner and how success will be checked. This turns an audit from a scary spreadsheet into an implementation plan. Without prioritization, technical SEO audits often become files that nobody finishes.
After changes, validate. Re-crawl affected sections, inspect sample URLs, test sitemaps, check logs and monitor search data over time. Technical SEO is not complete when a fix is deployed. It is complete when the site sends cleaner signals and no new problems were created.
Common Technical SEO Mistakes to Avoid
Many technical SEO issues come from overcorrection. A site owner sees duplicate content and noindexes too many archives. A developer sees crawl waste and blocks resources. A marketer sees a title recommendation and rewrites every title in the same formula. Good technical SEO is precise. It solves the real problem without damaging surrounding systems.
Another common mistake is confusing tools with outcomes. A green score in a plugin does not guarantee search success. A crawler warning does not always mean a ranking problem. A perfect sitemap does not make weak content valuable. Tools help you see the site, but judgment decides what the signals mean.
Migrations are especially risky. Domain moves, HTTPS changes, CMS rebuilds, permalink updates and redesigns can all create traffic loss if redirects, canonicals, internal links, sitemaps and tracking are not handled together. Build a migration checklist and test before launch. After launch, monitor closely for several weeks.
Finally, do not separate technical SEO from content quality. Search engines need access and clarity, but users need substance. A technically perfect thin page is still thin. The strongest sites combine clean architecture with useful content, real expertise and a fast, trustworthy experience.
A Repeatable Technical SEO Checklist
Use the following workflow when auditing a site or reviewing a major change. It is intentionally practical. You can run a light version monthly and a deeper version before migrations, redesigns or large content releases.
The order matters. Start with access and status codes before metadata. Confirm indexability before schema. Review templates before individual pages. This keeps you from polishing details while a larger technical issue remains unresolved.
- Confirm the preferred domain, HTTPS version, trailing slash policy and basic redirect behavior.
- Review robots.txt and make sure important resources and sections are not blocked accidentally.
- Check XML sitemaps for canonical, indexable, 200-status URLs only.
- Crawl the site and identify server errors, redirect chains, broken links and orphan pages.
- Inspect noindex, canonical and pagination behavior on important templates.
- Review title tags, meta descriptions and heading structure for duplicate or missing patterns.
- Evaluate internal links from navigation, hubs, breadcrumbs and contextual article links.
- Validate structured data against visible content and remove inaccurate markup.
- Test mobile rendering, JavaScript-dependent links and important content visibility.
- Re-check affected URLs after fixes and monitor search data for confirmation.
Frequently Asked Questions
What is technical SEO in simple terms?
Technical SEO is the work that helps search engines access, understand and index the right pages on a website. It includes crawlability, status codes, sitemaps, canonicals, internal links, structured data, mobile rendering and performance-related foundations.
Can technical SEO alone improve rankings?
Technical SEO can unlock visibility by removing barriers, but it does not replace useful content, authority and user satisfaction. A technical fix can help a valuable page perform better, while a weak page may still struggle even if the technical setup is clean.
How often should webmasters audit technical SEO?
A light review can happen monthly, while a deeper audit is useful quarterly or before major changes such as migrations, redesigns, new templates, CMS upgrades or large content imports. High-traffic sites may need more frequent monitoring.
Should every page be in the XML sitemap?
No. The sitemap should mainly include canonical, indexable, valuable URLs that return a 200 status. Redirects, noindex pages, internal search results, duplicate filters and broken URLs should generally stay out of the sitemap.
Are canonical tags the same as redirects?
No. A redirect sends users and crawlers to another URL. A canonical tag suggests the preferred version while users remain on the current URL. Canonicals are useful for duplicate or similar content, but redirects are better when an old URL should no longer be accessed.
What is the biggest technical SEO risk during a redesign?
The biggest risk is changing many signals at once: URLs, redirects, internal links, templates, metadata, canonicals, robots rules and tracking. A redesign should include a migration plan, pre-launch crawl, redirect map, post-launch validation and monitoring.
Advanced Technical SEO Workflow for Real Websites
Technical SEO is easiest to manage when it follows a workflow instead of a random list of checks. Start by identifying the pages that matter most: homepage, category hubs, high-traffic articles, commercial pages, comparison pages and evergreen resources that attract links. These URLs deserve deeper review because errors on them have a larger effect than warnings on low-value archives.
Next, crawl the site and compare what the crawler finds with what you expect to exist. Look for missing sections, unexpected parameter URLs, duplicate templates, redirect chains, blocked assets and pages that appear important but receive no internal links. A crawl is not just an error report; it is a map of how the site presents itself to search engines.
Then validate search signals on the page level. Check the index directive, canonical URL, status code, title, heading structure, structured data and internal links. One wrong directive can undo the value of a strong article. Technical SEO becomes more reliable when these signals are reviewed together rather than as separate tasks.
Finally, connect the technical review to real search behavior. Search Console can show whether important pages are receiving impressions, whether queries match intent and whether indexing coverage aligns with your expectations. A technically clean site should also make sense in search data. When the crawl and the performance report tell different stories, the investigation becomes more valuable.
Crawl Budget, Crawl Demand and Practical Control
Small and medium websites often worry about crawl budget before they need to, but crawl control still matters. The issue is not only how many pages search engines can crawl; it is whether the site is presenting its best URLs clearly. Thousands of thin tag pages, filter combinations or internal search URLs can distract attention from pages that deserve to rank.
Good crawl control begins with architecture. Important pages should be linked from logical hubs, navigation, breadcrumbs and related content. Low-value pages should not receive prominent internal links simply because a template generates them automatically. Crawlers follow links, so internal linking communicates priority even before a sitemap is considered.
Robots.txt can reduce crawling of certain paths, but it is not a complete indexing strategy. A blocked URL may still be discovered from external links, and blocking can prevent crawlers from seeing page-level signals. Use robots.txt carefully for clear crawl management, not as a substitute for fixing poor URL design.
XML sitemaps should contain canonical, indexable URLs that you actually want search engines to discover. If a sitemap includes redirected, noindexed or duplicate URLs, it sends a weak signal about site quality. Treat the sitemap as a curated list of important addresses, not a dump of every URL the system can generate.
Index Quality and the Problem of Too Many Weak Pages
A site can have an indexing problem even when many URLs are indexed. The question is whether the indexed pages represent useful destinations. Thin archives, duplicate tag pages, outdated search results, empty category pages and near-identical parameter URLs can make the site look unfocused. More indexed pages do not automatically mean more organic visibility.
Index quality reviews should classify pages by purpose. Some pages are meant to rank, some are meant to support navigation, some are required for users but not search, and some should not exist at all. Once the purpose is clear, the correct technical treatment becomes easier. A valuable guide may need stronger links; a duplicate filter page may need canonicalization or noindex; an obsolete page may need a redirect.
Do not remove or noindex pages only because they have low traffic. Some pages serve trust, support or conversion needs even if they are not search entry points. The decision should consider usefulness, uniqueness, internal demand and business value. Technical SEO is strongest when it improves clarity without damaging the user journey.
When cleaning a bloated index, move gradually and measure results. Large changes to categories, tags, canonicals or redirects can affect many URLs at once. Start with the most obvious low-value patterns, document the change and monitor coverage, impressions and crawl activity. Controlled cleanup is safer than a dramatic purge based on one report.
Internal Linking Systems That Scale
Internal links are not only decorations inside articles. They define topic relationships, distribute authority and help readers continue naturally. A scalable linking system uses hubs, related guides, breadcrumbs and contextual links together. Each type of link has a job: navigation helps orientation, breadcrumbs clarify hierarchy, hubs organize topics and contextual links explain the next useful step.
Anchor text should be descriptive without being mechanical. A link that says “technical SEO checklist” tells more than “click here,” but repeating the exact same phrase everywhere can look forced. Use natural variations that match the sentence. The goal is to help readers understand why the link is relevant before they click.
Old content should link to new content when the new piece genuinely expands the topic. Many sites publish new articles and forget to connect them from older pages that already receive traffic. This creates orphaned resources. A simple post-publishing routine can solve the issue: find five relevant existing pages and add helpful links where they fit.
Internal link audits should look for both missing links and excessive links. A page with dozens of unrelated links can dilute attention. A page with no links to deeper resources can trap the reader. Strong internal linking feels like guided exploration, not a list of keywords scattered through the text.
Structured Data Without Overcomplication
Structured data helps search engines understand page elements, but it should describe what is actually visible and useful. Adding schema that does not match the page can create confusion and may violate search guidelines. A webmaster should begin with the basics: Article, BreadcrumbList, Organization, Product, FAQ or HowTo only when the page genuinely supports those formats.
Validation tools are important, but passing validation is not the whole goal. Structured data can be technically valid while still being strategically unnecessary. Ask whether the markup clarifies the page, supports eligible rich results or improves consistency across templates. If it only adds complexity without a clear purpose, it may not be worth maintaining.
Template-level schema needs special care. A small mistake in a theme or plugin can replicate across hundreds of pages. Review sample pages from each template type after changes: article, category, product, author, search result, archive and landing page. This prevents one broken pattern from becoming a site-wide technical issue.
Structured data should be monitored after content changes. If an FAQ section is removed, the FAQ markup should be removed too. If product information changes, availability and price signals should remain accurate. Technical SEO is not only about adding markup; it is about keeping signals truthful over time.
Migration Checks That Protect Search Visibility
Site migrations are where technical SEO mistakes become expensive. A migration can involve a new domain, new CMS, new theme, URL restructuring, HTTPS changes or hosting changes. Each type has different risks, but the core principle is the same: preserve the relationship between old value and new destinations.
Before launch, create a URL inventory. Include important pages, backlinks, traffic pages, indexed URLs, media assets and special templates. Map old URLs to the best new equivalent, not simply to the homepage. Redirecting everything to the homepage may look easy, but it weakens relevance and frustrates users who expected a specific resource.
During launch, test status codes, canonicals, internal links, sitemap URLs, robots.txt, analytics, tracking events and mobile rendering. Search engines will discover the new structure quickly, so the first crawl should see a coherent site. Avoid launching with placeholder titles, blocked assets or unfinished redirects.
After launch, monitor daily at first. Watch coverage changes, crawl errors, rankings for brand terms, organic landing pages, server logs if available and user reports. Some fluctuation is normal, but persistent drops need investigation. The earlier a migration issue is found, the easier it is to correct before signals settle in the wrong direction.
Diagnosing Ranking Drops With Technical Evidence
A ranking drop should not be treated as one mystery with one answer. Start by identifying the pattern. Did one page decline, one template, one topic cluster or the whole site? Did impressions fall, clicks fall or average position move? Different patterns suggest different causes, and technical SEO should begin with evidence.
Review recent changes first. Content edits, template updates, plugin changes, redirect adjustments, robots.txt edits, canonical changes and hosting incidents can all affect visibility. A clear change log can shorten this investigation dramatically. Without a timeline, teams often blame algorithms before checking their own site history.
Compare affected pages with unaffected pages. If only pages using one template declined, the issue may be technical. If only articles in one topic declined, the issue may involve relevance or competition. If mobile performance worsened at the same time, experience may be part of the problem. Comparison prevents overreaction.
Do not rush into broad fixes. Changing titles, canonicals, internal links and content all at once makes it difficult to know what helped or harmed. Make the most likely correction first, document it and monitor. Technical recovery is usually a controlled process, not a dramatic reset button.
Technical SEO Governance for Editors and Developers
Technical SEO becomes stronger when editors and developers share simple rules. Editors should know how to choose useful titles, avoid duplicate topics, link to related resources and preserve important sections during updates. Developers should know which templates drive search traffic, which fields power metadata and which changes require validation before release.
Create publishing requirements that are easy to follow. Every new evergreen article should have a clear slug, descriptive title, summary, internal links, image alt text, category placement and a defined search intent. These rules prevent quality problems before they become audit findings. Prevention is more efficient than repairing hundreds of posts later.
Development workflows should include SEO acceptance checks. A new template is not complete until index directives, canonicals, headings, structured data, pagination, mobile rendering and performance have been reviewed. These checks do not need to slow the team if they are part of the normal release process.
Governance also means knowing when to say no. Not every filter, tag, widget, archive or landing page deserves to be crawlable. Not every campaign page should remain live forever. A healthy site has boundaries. The webmaster’s role is to keep the structure useful for people and understandable for search engines.
Reporting Technical SEO Progress Clearly
Technical SEO reports should avoid overwhelming people with every warning from every tool. The most useful report explains what changed, why it matters and what should happen next. Group findings by impact: critical issues affecting important pages, template-level improvements, index cleanup opportunities and longer-term architecture recommendations.
Use before-and-after evidence where possible. Show reduced redirect chains, cleaner sitemap counts, fixed broken links, improved crawl paths to key pages or corrected structured data. These examples make technical work visible. Stakeholders are more likely to support ongoing SEO when they can see concrete improvements.
Separate observations from decisions. “These tag pages receive no traffic and create duplicate paths” is an observation. “We should noindex them” is a recommendation. The distinction helps teams discuss trade-offs. Some pages may have business reasons to remain available even if they are not ideal search landing pages.
End the report with a prioritized action list. Each action should have an owner, expected benefit and level of risk. Technical SEO is a continuous discipline, but progress depends on completed tasks. A report that does not lead to action quickly becomes another unread document.
Faceted Navigation and Parameter URL Discipline
Faceted navigation can be helpful for users and messy for search engines. Filters for price, brand, date, color, rating, size or availability may create thousands of URL combinations. Some combinations are valuable landing pages, but many are temporary views with little unique content. A webmaster should decide which filter pages deserve indexable treatment and which should remain only as user navigation.
The decision should be based on search demand, content uniqueness and business value. A filtered category that represents a common query may deserve a clean URL, custom copy, internal links and a place in the sitemap. A random combination that produces three results probably should not compete for indexing. Technical SEO improves when the site intentionally promotes useful filtered pages instead of letting the system expose every possible combination.
Parameter handling should be consistent across templates. Mixed signals create confusion: one link uses a clean URL, another adds tracking parameters, another canonicalizes to a different version and another appears in the sitemap. Choose preferred patterns and apply them reliably. Consistency helps crawlers understand which version represents the page.
When changing faceted navigation, test both search and usability. Blocking every filter may make crawling cleaner but hurt visitors who rely on sorting and narrowing options. Allowing every filter may help users but weaken index quality. The best solution usually separates user controls from search landing pages, giving people flexibility while giving crawlers a focused structure.
Pagination, Archives and Large Content Libraries
Large sites need archive discipline. Categories, author pages, date archives and paginated lists can help discovery, but they can also create thin or repetitive paths. A webmaster should review whether each archive type serves a clear purpose. If an archive helps users find related work, keep it strong. If it exists only because the CMS created it automatically, reconsider how it is handled.
Pagination should remain crawlable when it leads to real content. Search engines need to reach older articles, products or resources through stable links. Infinite scroll can be convenient, but it should not hide deeper items from crawlers or users who cannot trigger scripts. Provide accessible links or paginated states when content depth matters.
Archive titles and descriptions should not be generic afterthoughts. A strong category page explains the topic, links to cornerstone resources and helps visitors choose where to go next. This turns an archive into a useful hub instead of a plain list. For a growing publication, category quality often becomes a major part of technical SEO.
Review archive performance periodically. Some categories become too broad, some become obsolete and some deserve to be split into clearer subtopics. Content libraries evolve, and technical structure should evolve with them. Better archives improve crawling, internal linking and reader navigation at the same time.
Final Thoughts
Technical SEO is most effective when it makes the site easier to understand. Search engines should not have to guess which pages matter, which versions are preferred, how content is connected or whether a URL is reliable. Users should not encounter broken paths, confusing redirects or slow templates.
Start with the fundamentals: clean access, truthful status codes, controlled indexing, useful internal links and accurate structured data. Then maintain those signals as the site grows. A technically healthy website gives every strong piece of content a better chance to be found.
Technical SEO Scenarios Webmasters Should Recognize
A traffic drop after a redesign often begins with changed URLs, missing redirects, altered internal links or accidental noindex directives. The visual design may be better, but search signals may have been reset. A pre-launch crawl and post-launch validation reduce this risk because they compare old and new structures before search engines discover the damage.
A bloated index can happen when tags, filters, search pages or parameter URLs become crawlable. The site may appear to have more pages, but many of them are weak. Search engines then spend attention on URLs that do not deserve to rank. Fixing this is not about hiding everything; it is about choosing the pages that represent the site well.
An orphan content problem appears when useful articles exist but receive no links from hubs, categories or related posts. These pages may be technically indexable, yet they feel unimportant. Internal linking can revive them by placing them inside a topic path where readers and crawlers naturally find them.
A canonical conflict can appear after template changes. A category may canonical to the homepage, a product variant may canonical to a discontinued item or a translated page may canonical to the wrong language version. These issues are not always visible to users, which is why template-level checks matter.
How to Explain Technical SEO to Non-Technical Teams
The simplest explanation is that technical SEO helps search engines reach the right doors and ignore the wrong ones. A website can have excellent writing, but if the doors are blocked, duplicated or mislabeled, discovery becomes harder. This framing keeps the conversation practical rather than mysterious.
Use analogies carefully. A sitemap is not a guarantee of indexing; it is more like a submitted list of important addresses. A canonical tag is not a redirect; it is a preference signal. Robots.txt is not a privacy lock; it is crawl guidance. Clear analogies prevent teams from using the wrong tool for the job.
Connect technical issues to business outcomes. Broken internal links waste reader attention. Slow templates reduce engagement. Indexing low-value pages dilutes the site’s search presence. Redirect mistakes lose the benefit of old links. When teams understand the consequence, they are more likely to support the fix.
Avoid overwhelming stakeholders with every crawl warning. Present the issues that affect important pages, large templates or revenue paths first. Technical SEO earns trust when it is prioritized, evidence-based and connected to visible outcomes.